指纹
指纹是Web应用程序测试的第一项任务。指纹识别将为渗透测试人员提供大量有用的信息,这将加剧其他漏洞,可能导致成功的开发。
指纹Web服务器
- 指纹识别Web服务器包括试图尽可能多地检索关于它的信息:
- 服务器的名称和版本。
- 是否在后端使用应用程序服务器?
- 数据库后端,是同一主机上的数据库。
- 使用反向代理。
- 负载均衡。
- 使用的编程语言。
检索服务器名称和版本可以通过检查HTTP标头轻松完成:
$ telnet vulnerable 80
GET / HTTP/1.1
Host: vulnerable
HTTP/1.1 200 OK
Date: Sun, 03 Mar 201173 10:56:20 GMT
Server: Apache/2.2.16 (Debian)
X-Powered-By: PHP/5.3.3-7+squeeze14
Content-Length: 6988
Content-Type: text/html
您也可以使用错误的Host标头(或仅使用IP)来获取默认的虚拟主机并获取更多信息:
$ telnet vulnerable 80
GET / HTTP/1.1
Host: thisisabadvalue
浏览网站
在指纹识别过程中执行的另一个操作是简单地浏览网站并跟踪发现的任何有趣的功能:
- 上传和下载功能。
- 身份验证表单和链接:登录,注销,密码恢复功能。
- 管理部分。
- 数据输入点:“发表评论”,“联系我们”表格。
在此阶段,检查网页的源代码并搜索HTML注释很有趣。评论通常提供有关该网站的有趣信息。所有浏览器都允许您访问网页的来源。然后您可以搜索HTML注释标签:即介于<!--和之间的信息-->。大多数情况下,源代码都是彩色的,评论很容易找到:

网站使用的文件扩展名将为您提供有关正在使用哪种技术的更多信息:
- 如果你看到.php文件,应用程序是用PHP编写的;
- 如果你看到.jsp或.do文件,应用程序是用Java编写的;
- ...
很明显,有人可以用`.php`扩展名或带有`.do`扩展名的PHP应用程序编写一个Java应用程序,但实际上并不太可能。
也可以通过查看动作映射到URL的方式来指纹网站。例如,在Ruby-On-Rails中,开发人员可以使用"框架"自动生成代码来管理给定对象的视图(HTML代码),模型(存储逻辑)和控制器(业务逻辑)。这将生成一个URL映射,其中:
- /objects/ 会给你一个所有对象的列表;
- /objects/new 会给你创建一个新对象的页面;
- /objects/12 会给你的对象与ID 12;
- /objects/12/edit 会给你页面修改id为12的对象;
- ...
检查favicon.ico
favicon.ico是您访问网站时在浏览器网址栏中可以找到的这张小图片:
由于大多数开发人员或系统管理员不会更改它,并且大多数应用程序或服务器都提供它们,因此此图片可用作指纹识别元素。例如,Drupal使用下面的favicon。

检查robots.txt文件
部署在应用程序中的另一个常见文件是robots.txt。一些基于PHP的应用程序大量使用robots.txt,以防止搜索引擎索引应用程序的某些部分。它们是一个非常好的信息来源,可用于映射应用程序的有趣部分,并找出用于构建网站的框架或应用程序。
例如,robots.txt CMS Joomla使用以下内容:
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/它还会告诉你你应该检查什么。如果一个网站不想索引某个东西,那可能是因为它在安全方面很有意思或者说有什么不想让人看到的东西。
搜索目录和页面
浏览网站后,搜索不能通过链接直接获得的页面或目录很重要。为此,您需要使用文件名列表并检查这些名称是否存在于远程服务器上。
目录/页面破坏
工具Wfuzz(http://www.edge-security.com/wfuzz.php)可用于使用公共资源名称的词表检测Web服务器上的目录和页面。
可以运行以下命令来检测远程文件和目录:
$ python wfuzz.py -c -z file,wordlist/general/common.txt --hc 404 http://vulnerable/FUZZ
你可以用Wfuzz做很多事情:
- 根据错误代码进行过滤。
- 只搜索具有给定扩展名的文件:http://vulnerable/FUZZ.php。
- 蛮力证书。
- ...
和其他任何工具一样,学习的最佳方式就是和它一起玩,看看你能做什么。
查找管理页面
大多数管理页面都是众所周知的URL,可以使用目录解析器找到。然而,保持每个技术/服务器的管理页面列表总是非常方便。您也可以查看产品/项目文档以获取此信息。
在您的管理页面列表中,保留有关与之配合使用的默认凭证的信息。
生成错误
生成404错误可以为您提供有关托管Web应用程序的后端的大量信息。例如,为了生成错误,您只需要在请求的URL中输入一个随机字符串randomlongstring。
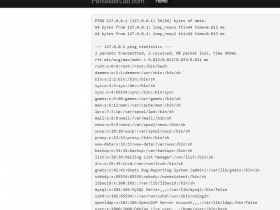
服务器的配置可以明显改变这种行为,但如果服务器是Tomcat,这将是你将得到的页面,包含404错误:
对于Ruby-on-Rails也是如此:

有很多不同的方法可以在Web应用程序中生成错误。例如,通过添加一些特殊字符(如NULL字节(%00),单引号(%27)或双引号(%22)),您可能会产生错误。您也可以从HTTP请求中删除一个值。一旦你设法得到错误页面,你就可以更多地了解你正在攻击的内容(例如Tomcat):
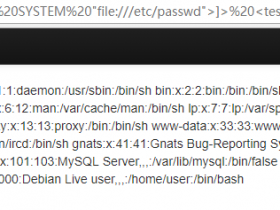
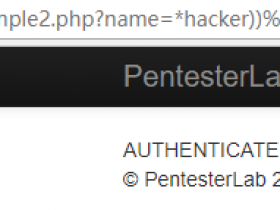
任何可以修改应用程序行为并生成错误的方法都是检索信息的好方法。用PHP应用程序进行简单测试就是替换/index.php?name=hacker为/index.php?name[]=hacker。会出现类似如下图错误:

关键之一是能够读取错误。这听起来很愚蠢,但即使错误信息不同,你会惊讶于有多少人认为两个错误是相同的:“魔鬼在细节中”。
保存信息
任何信息都应该保存,一切都应该保存:
- 远程服务器上的路径。
- 错误消息。
- 使用数据库后端。
- headers头中披露的内部IP地址。
- 一切,...
保存信息通常会帮助您利用另一个漏洞。例如,如果您需要知道应用程序在服务器上的存储位置,则可能已经有了这些信息,这要归功于来自应用程序另一部分的错误消息。