今天一位群友在运行AI绘画软件“Stable Diffusion”的时候,结果报错类似如下:
RuntimeError: CUDA error: device kernel image is invalid
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
中文翻译
运行时错误:CUDA错误:设备内核映像无效
CUDA内核错误可能会在其他一些API调用中异步报告,因此下面的 stacktrace 可能不正确。
对于调试,请考虑传递 CUDA_LAUNCH_BLOCKING=1 。
使用“TORCH_USE_CUDA_DSA”进行编译以启用设备端断言。

原因
通过上面的报错,也能知道一个最主要的原因就是:CUDA错误:设备内核映像无效。
后来,我又向这位朋友要到了整个“控制台”的代码,如下:
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
Commit hash: 22bcc7be428c94e9408f589966c2040187245d81
Installing requirements for Web UI
Launching Web UI with arguments: --medvram --theme dark --xformers --api --autolaunch
AUTOMATIC1111/stable-diffusion-webui packed by bilibili@秋葉aaaki
本整合包完全免费,严禁倒卖。若您付费获得本软件请立刻举报商家。
[AddNet] Updating model hashes...
[AddNet] Updating model hashes...
Loading weights [7f96a1a9ca] from G:\SD\sd-webui-aki-v4\models\Stable-diffusion\anything-v5-PrtRE.safetensors
Creating model from config: G:\SD\sd-webui-aki-v4\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Loading VAE weights specified in settings: G:\SD\sd-webui-aki-v4\models\VAE\animevae.pt
Applying xformers cross attention optimization.
Textual inversion embeddings loaded(1): EasyNegative
Model loaded in 71.2s (load weights from disk: 1.6s, create model: 1.1s, apply weights to model: 55.3s, apply half(): 5.6s, load VAE: 6.8s, hijack: 0.1s, load textual inversion embeddings: 0.5s).
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 98.8s (import torch: 4.3s, import gradio: 3.9s, import ldm: 1.8s, other imports: 4.8s, setup codeformer: 0.3s, load scripts: 3.1s, load SD checkpoint: 71.3s, create ui: 8.2s, gradio launch: 0.8s, scripts app_started_callback: 0.1s).
Error completing request
Arguments: ('task(q4qks2qdumkiupn)', '', '', [], 20, 0, False, False, 1, 1, 7, -1.0, -1.0, 0, 0, 0, False, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, [], 0, False, 'MultiDiffusion', False, 10, 1, 1, 64, False, True, 1024, 1024, 96, 96, 48, 1, 'None', 2, False, False, False, False, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, False, True, True, False, 1536, 96, False, False, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, None, 'Refresh models', <scripts.external_code.ControlNetUnit object at 0x0000012F44116620>, <scripts.external_code.ControlNetUnit object at 0x0000012F44116650>, <scripts.external_code.ControlNetUnit object at 0x0000012F441166E0>, <scripts.external_code.ControlNetUnit object at 0x0000012F44116770>, False, False, 'positive', 'comma', 0, False, False, '', 1, '', 0, '', 0, '', True, False, False, False, 0, None, False, None, False, None, False, None, False, 50) {}
Traceback (most recent call last):
File "G:\SD\sd-webui-aki-v4\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "G:\SD\sd-webui-aki-v4\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\modules\txt2img.py", line 56, in txt2img
processed = process_images(p)
File "G:\SD\sd-webui-aki-v4\modules\processing.py", line 503, in process_images
res = process_images_inner(p)
File "G:\SD\sd-webui-aki-v4\modules\processing.py", line 642, in process_images_inner
uc = get_conds_with_caching(prompt_parser.get_learned_conditioning, negative_prompts, p.steps, cached_uc)
File "G:\SD\sd-webui-aki-v4\modules\processing.py", line 587, in get_conds_with_caching
cache[1] = function(shared.sd_model, required_prompts, steps)
File "G:\SD\sd-webui-aki-v4\modules\prompt_parser.py", line 140, in get_learned_conditioning
conds = model.get_learned_conditioning(texts)
File "G:\SD\sd-webui-aki-v4\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py", line 669, in get_learned_conditioning
c = self.cond_stage_model(c)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack_clip.py", line 229, in forward
z = self.process_tokens(tokens, multipliers)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack_clip.py", line 254, in process_tokens
z = self.encode_with_transformers(tokens)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack_clip.py", line 302, in encode_with_transformers
outputs = self.wrapped.transformer(input_ids=tokens, output_hidden_states=-opts.CLIP_stop_at_last_layers)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1538, in _call_impl
result = forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\transformers\models\clip\modeling_clip.py", line 811, in forward
return self.text_model(
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\transformers\models\clip\modeling_clip.py", line 708, in forward
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\transformers\models\clip\modeling_clip.py", line 223, in forward
inputs_embeds = self.token_embedding(input_ids)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack.py", line 234, in forward
inputs_embeds = self.wrapped(input_ids)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\sparse.py", line 162, in forward
return F.embedding(
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\functional.py", line 2210, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA error: device kernel image is invalid
提示:Python 运行时抛出了一个异常。请检查疑难解答页面。
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
Error completing request
Arguments: ('task(12np73tygyxboil)', '猪', '', [], 20, 0, False, False, 1, 1, 7, -1.0, -1.0, 0, 0, 0, False, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, [], 0, False, 'MultiDiffusion', False, 10, 1, 1, 64, False, True, 1024, 1024, 96, 96, 48, 1, 'None', 2, False, False, False, False, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, 0.4, 0.4, 0.2, 0.2, '', '', 'Background', 0.2, -1.0, False, False, True, True, False, 1536, 96, False, False, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, 'LoRA', 'None', 1, 1, None, 'Refresh models', <scripts.external_code.ControlNetUnit object at 0x0000012F44116620>, <scripts.external_code.ControlNetUnit object at 0x0000012F44116650>, <scripts.external_code.ControlNetUnit object at 0x0000012F441166E0>, <scripts.external_code.ControlNetUnit object at 0x0000012F44116770>, False, False, 'positive', 'comma', 0, False, False, '', 1, '', 0, '', 0, '', True, False, False, False, 0, None, False, None, False, None, False, None, False, 50) {}
Traceback (most recent call last):
File "G:\SD\sd-webui-aki-v4\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "G:\SD\sd-webui-aki-v4\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\modules\txt2img.py", line 56, in txt2img
processed = process_images(p)
File "G:\SD\sd-webui-aki-v4\modules\processing.py", line 503, in process_images
res = process_images_inner(p)
File "G:\SD\sd-webui-aki-v4\modules\processing.py", line 642, in process_images_inner
uc = get_conds_with_caching(prompt_parser.get_learned_conditioning, negative_prompts, p.steps, cached_uc)
File "G:\SD\sd-webui-aki-v4\modules\processing.py", line 587, in get_conds_with_caching
cache[1] = function(shared.sd_model, required_prompts, steps)
File "G:\SD\sd-webui-aki-v4\modules\prompt_parser.py", line 140, in get_learned_conditioning
conds = model.get_learned_conditioning(texts)
File "G:\SD\sd-webui-aki-v4\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py", line 669, in get_learned_conditioning
c = self.cond_stage_model(c)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack_clip.py", line 229, in forward
z = self.process_tokens(tokens, multipliers)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack_clip.py", line 254, in process_tokens
z = self.encode_with_transformers(tokens)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack_clip.py", line 302, in encode_with_transformers
outputs = self.wrapped.transformer(input_ids=tokens, output_hidden_states=-opts.CLIP_stop_at_last_layers)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1538, in _call_impl
result = forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\transformers\models\clip\modeling_clip.py", line 811, in forward
return self.text_model(
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\transformers\models\clip\modeling_clip.py", line 708, in forward
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\transformers\models\clip\modeling_clip.py", line 223, in forward
inputs_embeds = self.token_embedding(input_ids)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\modules\sd_hijack.py", line 234, in forward
inputs_embeds = self.wrapped(input_ids)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\modules\sparse.py", line 162, in forward
return F.embedding(
File "G:\SD\sd-webui-aki-v4\py310\lib\site-packages\torch\nn\functional.py", line 2210, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA error: device kernel image is invalid
提示:Python 运行时抛出了一个异常。请检查疑难解答页面。
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
解决方法
既然说是“CUDA错误:设备内核映像无效。”,那我们就去手工安装CUDA。
具体的操作步骤如下:
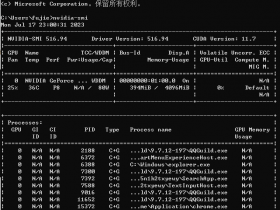
1、命令行运行命令:nvidia-smi,查看自己显卡支持的 CUDA版本,升级显卡驱动有可能会让你支持更高版本的 CUDA。
2、然后前往英伟达 CUDA 官网,下载对应版本。
英伟达 CUDA 官方下载网址:https://developer.nvidia.com/cuda-downloads
英伟达CUDA各版本官方下载地址:https://developer.nvidia.com/cuda-toolkit-archive
注意:
你对应的版本号最高的版本,比如我的是12.0的,那就下12.0.1(这里最后的.1意思是,11.7版本的1号升级版),总之一句话,下载的版本比12.0低就行了。

3、选你自己的操作系统版本,选择离线安装包“exe [local]”。
(这张图忘记截了,从网上找了一张类似的,区别只是图中版本是11.7.1)

4、后面只需要安装即可!
如果你还有不懂的,具体操作请参考:CUDA下载与安装教程