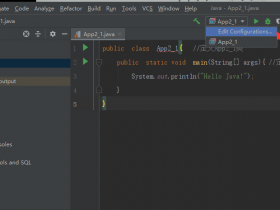
我的 App2_1.java 代码如下:
public class App2_1{ //定义App2_1类
public static void main(String[] args){ //定义主方法
System.out.println("Hello Java!");
}
}
结果,我用 javac 编译的时候,提示如下:
D:\Java>javac ./example/App2_1.java
.\example\App2_1.java:1: 错误: 编码 GBK 的不可映射字符 (0xBB)
public class App2_1{ //瀹氫箟App2_1绫?
.\example\App2_1.java:2: 错误: 编码 GBK 的不可映射字符 (0x95)
public static void main(String[] args){ //瀹氫箟涓绘柟娉?
2 个错误

原因:
通过上图的说明,稍微有一点编程的基础,相信大家也知道主要的原因了,主要就是编码的问题。
解决方法
关于 javac 编译 出现编码的问题,解决方法有如下两种:
第一种方法:
1、记事本打开 App2_1.java 源文件,另存为“ANSI”编码。
只要你的源文件里面有中文,都可以用“ANSI”这个编码。

2、DOS窗口再执行 javac 编译 命令:
D:\Java>javac ./example/App2_1.java
 、
、
3、上图中没有报错,为空换行。D:\Java\example 有了 App2_1.class 就算编译成功,

第二种方法:
有些人可能会想,我的 App2_1.java 代码源文件,我就想设置为 UTF-8 编码。难道不行吗?又应该如何操作?具体如下:
1、DOS窗口直接执行 javac 编译命令:
D:\Java>javac -encoding UTF-8 ./example/App2_1.java
2、跟上面一样,没有报任何的错误,空格换行、出来了 App2_1.class 文件就是编译成功。
总结:
ANSI:美国国家标准协会,系统预设的标准文字储存格式。简体中文编码GB2312,实际上它是ANSI的一个代码页936。
UTF-8:通用字集转换格式,这是为传输而设计的编码,2进制,以8位为单元对Unicode进行编码,如果使用只能在同类位元组内支持8个位元的重要资料一类的旧式传输媒体,可选择UTF-8格式。
在UTF-8里,英文字符仍然跟ASCII编码一样,因此原先的函数库可以继续使用。而中文的编码范围是在0080-07FF之间,因此是2个字节表示(但这两个字节和GB编码的两个字节是不同的),用专门的Unicode处理类可以对UTF编码进行处理。